DeepSeek的负担能力是一个神话:革命性的AI实际上花费了16亿美元
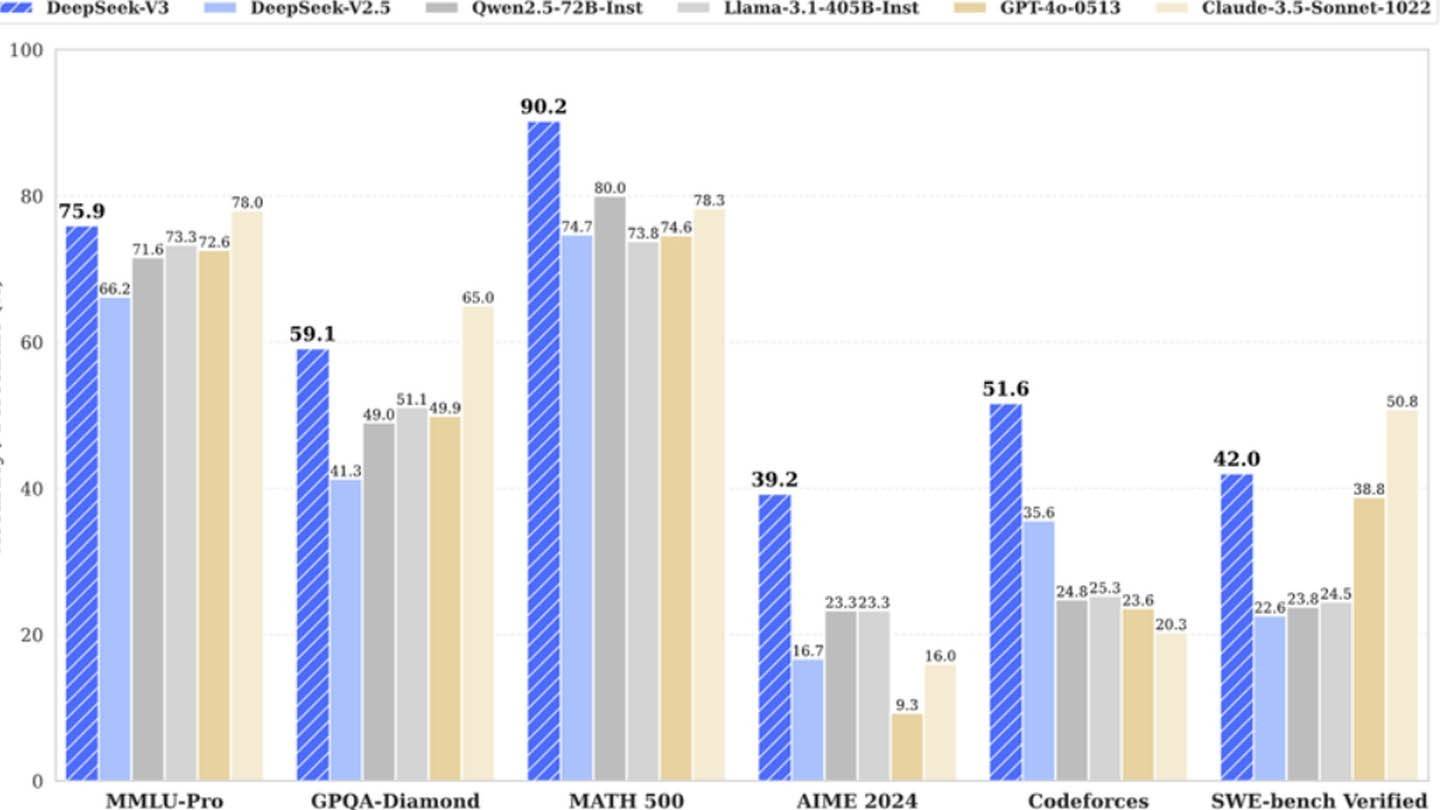
DeepSeek的廉价AI模型令人惊讶地挑战了行业巨头。这家中国初创公司声称已经培训了其强大的DeepSeek V3神经网络,仅利用2048 GPU,大大削弱了竞争对手,仅需600万美元。然而,这似乎很低的成本掩盖了更多的投资。
 图像:ensigame.com
图像:ensigame.com
DeepSeek V3的创新架构有助于其效率。关键技术包括用于同时单词预测的多态预测(MTP),使用256个神经网络的专家(MOE)进行加速训练的混合物(MOE)以及多头潜在注意(MLA)(MLA),以改善信息提取。
 图像:ensigame.com
图像:ensigame.com
但是,一份半分析报告显示,基础设施大得多:约有50,000名NVIDIA GPU,耗资约16亿美元,运营费用接近9.44亿美元。这与公开的600万美元培训成本形成鲜明对比,这仅反映了培训前的GPU使用情况,不包括研究,改进,数据处理和整体基础设施。
DeepSeek的独立性和高效结构是高级对冲基金的子公司,是其成功的关键。拥有其数据中心可以优化模型开发和快速创新。公司的自筹资金和精益结构也有助于其敏捷性。对于一些研究人员来说,高薪高薪,每年超过130万美元,吸引了中国大学的顶尖人才。
 图像:ensigame.com
图像:ensigame.com
尽管DeepSeek的600万美元索赔具有误导性,但与竞争对手相比,其实际投资超过5亿美元仍然代表了巨大的成本优势。该公司的R1型号的培训花费了500万美元,而Chatgpt-4据说耗资1亿美元。 DeepSeek的成功强调了一家资金充足,独立的AI公司的竞争潜力,尽管其“预算友好”的叙述需要资格。
 图像:ensigame.com
图像:ensigame.com
总之,DeepSeek的竞争优势源于大量投资,技术创新和高技能的团队的结合,而不仅仅是培训预算非常低。但是,即使有了校正的数字,其成本仍然大大低于其竞争对手的成本。
-
 PokémonGo的爱好者在孟买,为令人难忘的庆祝活动做准备! PokémonFiesta将于3月29日和30日在Lower Parel的Phoenix Palladium举行,为所有PokémonFans提供了两天的乐趣,冒险和独家游戏内内容,以了解所有神奇宝贝。作者 : Savannah Apr 04,2025
PokémonGo的爱好者在孟买,为令人难忘的庆祝活动做准备! PokémonFiesta将于3月29日和30日在Lower Parel的Phoenix Palladium举行,为所有PokémonFans提供了两天的乐趣,冒险和独家游戏内内容,以了解所有神奇宝贝。作者 : Savannah Apr 04,2025 -
 对于RPG爱好者而言,令人振奋的消息 - 康纳米和米尔特里(Konami)刚刚推出了Suikoden Star Leap,这是一个新鲜的移动RPG,旨在在Android和iOS设备上推出。尽管尚未披露特定的发布日期,但急切的预期游戏将可以免费玩作者 : Patrick Apr 04,2025
对于RPG爱好者而言,令人振奋的消息 - 康纳米和米尔特里(Konami)刚刚推出了Suikoden Star Leap,这是一个新鲜的移动RPG,旨在在Android和iOS设备上推出。尽管尚未披露特定的发布日期,但急切的预期游戏将可以免费玩作者 : Patrick Apr 04,2025


















![[777Real]スマスロモンキーターンⅤ](https://images.0516f.com/uploads/70/17347837276766b2efc9dbb.webp)